- ScanSnap よくあるご質問 > 購入を検討されているお客様 > 購入 > ScanSnapで作成したPDFデータは、文書(テキスト)の選択・検索ができますか?
ScanSnapで作成したPDFデータは、文書(テキスト)の選択・検索ができますか?
- カテゴリー :
-
- ScanSnap よくあるご質問 > 購入を検討されているお客様 > 購入
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > iX500
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > S1100
- ScanSnap よくあるご質問 > 機種から選ぶ > SV600
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > S1500
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > S1500M
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > S1300i
- ScanSnap よくあるご質問 > 機種から選ぶ > 販売終了機種 > S1300
- ScanSnap よくあるご質問 > 機種から選ぶ > iX100
回答
装置に添付されているソフトウェアを使用し、文字認識を行うことで文書(テキスト)の選択や検索ができます。
文字認識を行うには、以下の装置に添付されているソフトウェアを使用して設定します。
- Windows用ソフトウェア:
ScanSnap Manager、ScanSnap Organizer - macOS用ソフトウェア:
ScanSnap Manager
ScanSnapで読み取り保存されたPDFは、標準設定ではすべて画像ファイルとなります。
文字認識をするには、検索可能なPDFにする設定が必要です。
ただし、ScanSnap iX500/iX100で以下の読み取りを行う場合、検索可能なPDFを作成できません。
- Wi-Fi経由でモバイル機器と直接接続した場合
- コンピューターにScanSnap Connect Applicationをインストールして、ScanSnap Connect Application経由でWi-Fi接続した場合
【スキャン時に検索可能なPDFに変換する方法】
Windowsの場合
ScanSnap Managerの「ファイル形式」タブの「検索可能なPDFにします」にチェックを付けて「対象ページ」で「先頭ページ」または「全ページ」を選択します。

【対象言語(Windows)】
日本語/英語/フランス語/ドイツ語/イタリア語/スペイン語/中国語(簡体字)/中国語(繁体字)/韓国語/ロシア語/ポルトガル語
macOSの場合
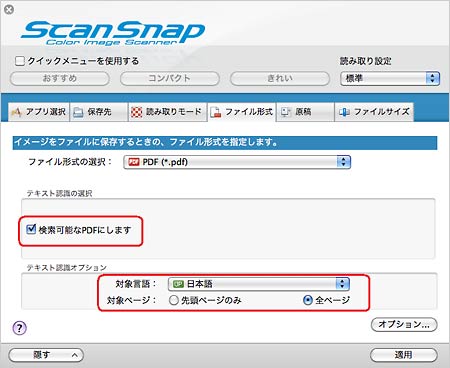

【対象言語(macOS)】
日本語/英語/フランス語/ドイツ語/イタリア語/スペイン語/ロシア語/ポルトガル語
【保存済みのPDFデータを後からScanSnap Organizerで検索可能なPDFに変換する方法】
Windowsの場合
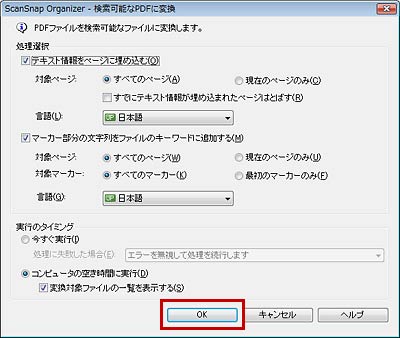
1.文字認識したいPDFデータを選択し、 [ホーム]タブから「検索可能なPDFに変換」アイコンをクリックして「選択中のPDFを変換」をクリックします。

2.検索可能なPDFに変換する条件を指定して[OK]ボタンをクリックします。